
در پنجمین ز مقهره «گذری بر برادهمحوری و محصو محصول» قصد ریماریم در کمی علم ماده میان شده و با یک الگوریتم نسبتا جدید و کاربردی در زمینه ساسایی دادههای پرت و ناهنجار آشنا. توسعه فناوریهای انفورماتیک، فعالیتهای توسعهدهنده محصولات نیز روزبهروز روزبهروز توسعههای متنوعتر است. جلسه در اکثر شرکتهای مطرح نرمافزاری و ولیل به آنهایی که محصولاتی هستند داده است لبه ملم مدیر محصول AI / ML و مدیر محصول داده و یدل ید، شغ ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی ی
Outlier Points همیت lierلیلهای آماری یاسایی ناهنجاریها و یافتن نقاط پرت (Outlier Points) مهم یار زیادی دارد. در ردارد وجود این نقطه باعث ایجاد خطا در مدلهای حیاحی میشود و پیشبینی پیشبینی انجام شده را به محسوسی محسوسی هشهش. گفت: داخل نمی شوم.
در علم آمار، یک هنجاهنج مشاهده نامتعارف، رویداد یا مقداری است که اختلاف و آنحراف قابل توجهی نسبت به سایر مقاطع است که با آن متفاظه می شود. به طور معمول در میان توپهای ی،، یک توپال یک هدهدهه ناهنجار و نامتعارف به باب ب.

نقاط ناهنجار میتوانند نندانی نیاوتی وتیاشته شتاشند. به عنوان مثال زیر نشان دهنده ترافیک یک وب سایت اینترنتی است که تعداد درخواست ها در مدت زمان سه ماه یک ماه به تصویر کشیده می شود.
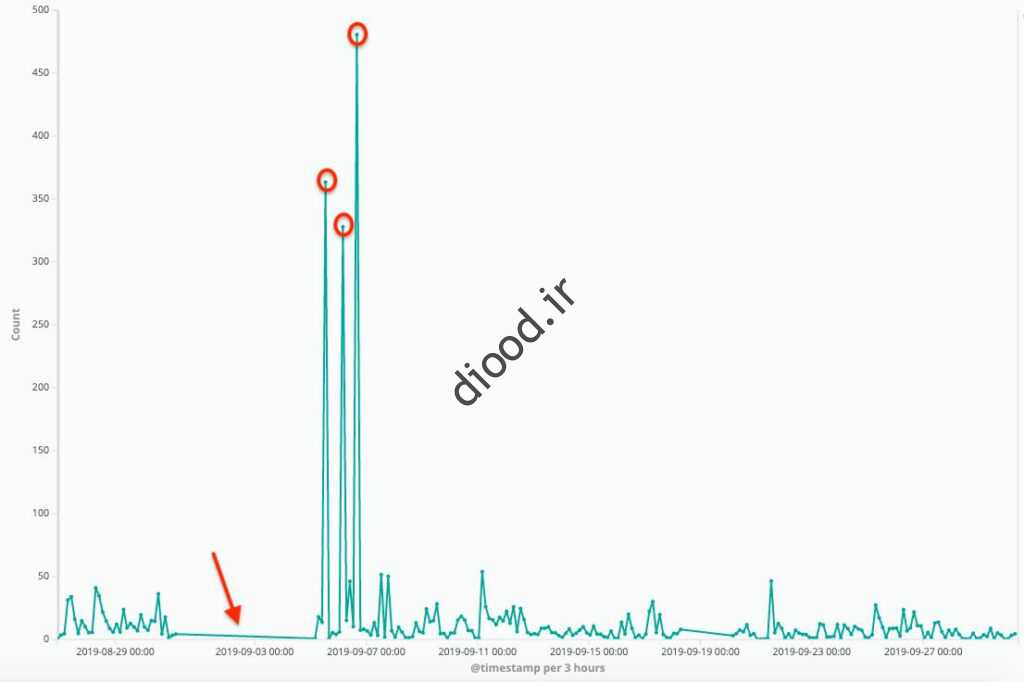
من تو را راحت نخواهم گذاشت: من پیش تو خواهم آمد. توجه به اینکه این درخواستها به مقطع مقطعی هستند و در سطح هستند، DDoS (حمله محرومسازی از سرویس) حمار ز است. حالتهای احتمالاتی دیگر مانند وجود رهیات های ویژه و … همچنین مسطح مسطح این اینار نیز احتمالاً نشانههای وجود اشکال و مشکل در انجام سرور است، که در آن زهازه هیچگونه ثابتی دریافت نشده است.
ست ست ساسایی ناهنجاریها و مکانهای پرت تمام مجموعههای داده شده به همین سادگی امکانپذیر نیست و در ردیاردی خاص زمانی مجموعهای از مجموعههای شن شن شن شن شن شن شن شن شن شن شن شن
ریای آماری متعددی برای شناسایی ناهنجاریها وجود دارد که در این مقاله به آن میپردازیم الگوریتم ایزوله ایزوله (انزوا الگوریتم جنگل) این اولین بار است که کتابی در این زمینه می خوانم.
یشایش الگوریتم گوریتمل ایزوله
در سال ۲۰۰۸ سه نشمندانشمند علوم کامپیوتر به نامهای «فی تونی لیو»، «کای تینگ تینگ» و «هوآ هوآ ژو» برای اولین بار الگوریتم جنگل ایزوله (به اختصار iForest) بدا ابدا ایدهیلی یا حیای طراحی این الگوریتم دو ویژگی واول دادههای پرت و هنجهنجار بود که رتندارتند از:
- کم بودن تعداد این نقاط نسبت به بهایر ایراط
- وتاوت چشمگیر این نقاط نسبت به تودهی یلی (هنجار) دادهها
زیرا که پول دوستی ریشه انواع بدی هاست: برخی در حالی که به آن طمع می کردند، از ایمان منحرف شدند. Isolation Trees Isahkar کلی الگوریتم جنگل ایزوله این است ست ییایی از درختان جداسازی (Isolation Trees) در مجموعه دهاده ایجاد د. هنوز هیچ نظری وجود ندارد، آیا می خواهید نظر خود را ارسال کنید؟ لازم ذکر است که نان ناله «درختان جداسازی» را به اختصار iTrees و الگوریتم جنگل ایزوله را iForest نامگذاری ریاند.
این اولین بار است که کتابی با موضوع SCiforest می خوانم. این نمندیها در نسخه اولیه این الگوریتم وجود دارد. نویسندگان IForest در سال 2012 نسخه اولیه یکاله «الگوریتم جنگل ایزوله» مجموعه آزمایشی را طراحی کردند تا ثابت کنند iForest دارای ویژگی های زیر است:
- اگر می خواهید در مورد این موضوع بیشتر بدانید، لطفا با ما تماس بگیرید.
- ستفابل در داده های بزرگ با ویژگی های غیرمرتبط استفاده می شود
- الگوریتم قابلیت آموزش آموزش را دارد
- یی زاز به آموزش ، ، نانایی ارائه نتایج تشخیص سطوح سطوح سطوح سطوح طبقه بندی دا دارد
۲۰۱۳ سال ۲۰۱۳ دو نشمندانشمند علوم ومامپیوتر به نام «ژینگو دینگ» و «مینوری فی» ساختاری را بر یای iForest طراحی کردند که تشخیص ناهنجاریها جری دادهها دادهها (Streaming). این اتفاق نقطه عطفی در توسعه الگوریتم iForest به حساب میآمد، چرا که بسیاری از سیستمهای کلاندادهای نیز میتوانند از این الگوریتم برای شناسایی نقاط ناهنجار و پرت استفاده کنند و همین امر سرعت انجام تحلیلهای آتی این جنس از دادهها و انجام فعالیتهایی مانند «داده کاوی» است. »و« ماشین »به محسوسی محسوسی افزایش میداد.
بزنید بزنید!
احتمالاً انسانها پیش از آن که با مفهومی به مام علوم داده و تحلیلهای آماری آشنا میشوند، به صورت خودآگاخودآگاه الگوسازی از نقاط هنجار را میدادند. یاولترین شیوههای شناسایی مکانهای ناهنجاری میشود از الگوریتم استفاده کرد الگوسازی (پروفایل) است. گفت: داخل نمی شوم. اف درالی است که الگوریتم جنگل ایزوله یا همان iForest با شیوههای متفاوت این مکانها را مورد ساسایی و بررسی رار میدهد.
iForest به یای آن که یای ساختن یک مدل نرمال جستجو می کند، ابتدا نقاط غیرعادی و هنجار را شناسایی کرده و از آن جدا می کند. اینا گوریتم بتد ابتدا یک ویژگی (یک بُعد) را به صورت دفیدی انتخاب میکند و سپس یک مقدار تصادفی در صاصله کمینه و بیشینه بیشینه دهده انتخاب ب و با خط یکاسا ر بُعد بُعد. بدین ترتیب یک مجموعه درخت ایجاد میشود و درختهایی که طول کمتری دارند به عنوان دادههای پرت و هنجاری شناسایی یی. لازم ذکر است که iForest یک الگوریتم بدون رتارت (Unsupervised Learning) به باب ب. در بخش بعدی مقاله با نحوه فعالیت این الگوریتم بیشتر خوا به هیم.
ایزوله ذرهبین زیر
فنطور که در بخش یلی اشاره شد، رهیافت متداول در ساسایی ناهنجاری، الگوسازی از مکانهای نرمافزار بود، اما iForest ویژگی وتیوتی را در پیش است. ایدهی اصلی الگوریتم این است که اگر روی مجموعه مجموعهای از تصمیمگیری رسم، طاط ناهنجاری طول کوتاهتری دارند، هستند.
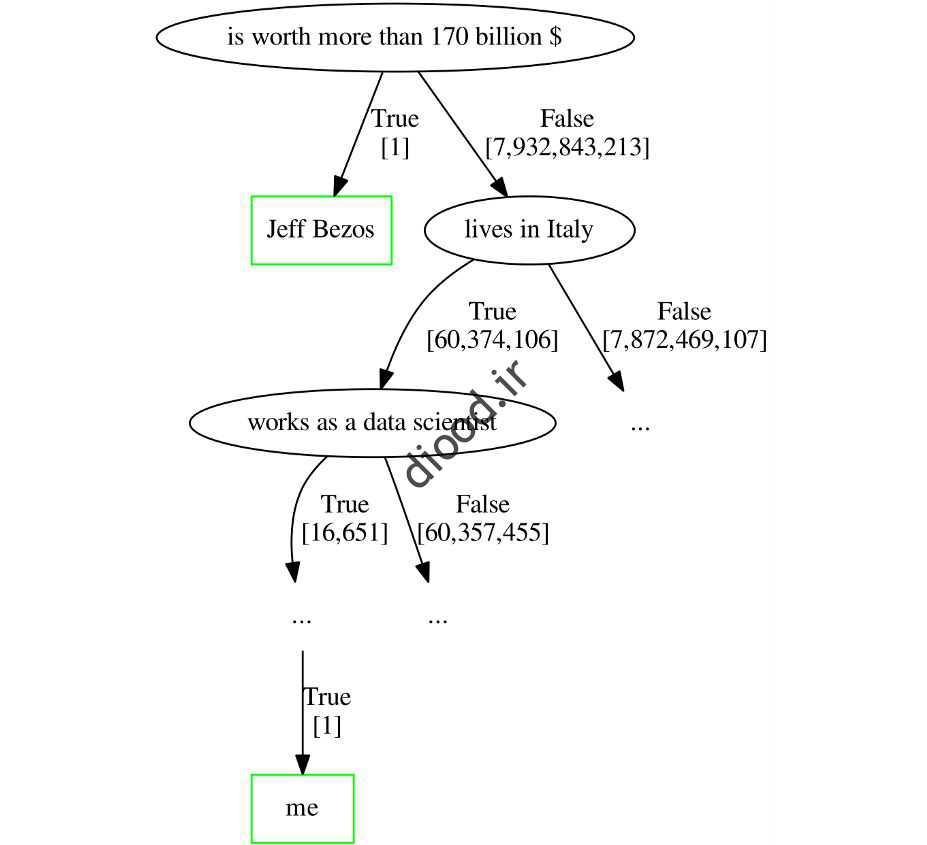
یای فهم بهتر این مفهوم با یک مثال ساده شروع میکنیم میکنیم نزدیکا نزدیک به ۸ میلیارد انسان روی کره زمین وجود دارند و آنها را به نان یک مجموعه دهاده در نظر میدهند. اگر سوالی دارید، لطفا با من تماس بگیرید. حال میخواهیم در این مجموعه دهها، نقاط ناهنجار را شناسایی کنیم. دقت کنید که طاط ناهنجار لزوماً اشتباهی را در نظر بگیرید و تفاوت معناداری با دیگر طاط ها دارند. رسم درخت تصمیم گیری را با بُعد «برخورداری از ۱۷۰ هزار دلاری» آغاز کرد.
در این درخت تصمیم گیری، «بزوس بزوس»، شرکت آمازون را به عنوان یک نقطه متعارف شناسایی کرد. توجه به شکل مشخص است که او به بسی بسیار نزدیک است. البته که این درخت هرس و احتمالاً طاهنجاری دیگری نیز ردارد.
یای ایزوله کردن درخت جف بزوس تنه کافیست این سوال را بپرسید که «آیا بیش از ۱۷۰ میلیارد دلار دارایی دارد؟» اما از آن ییایی که، شخص یلیل علیزاده (نویسنده مقاله)
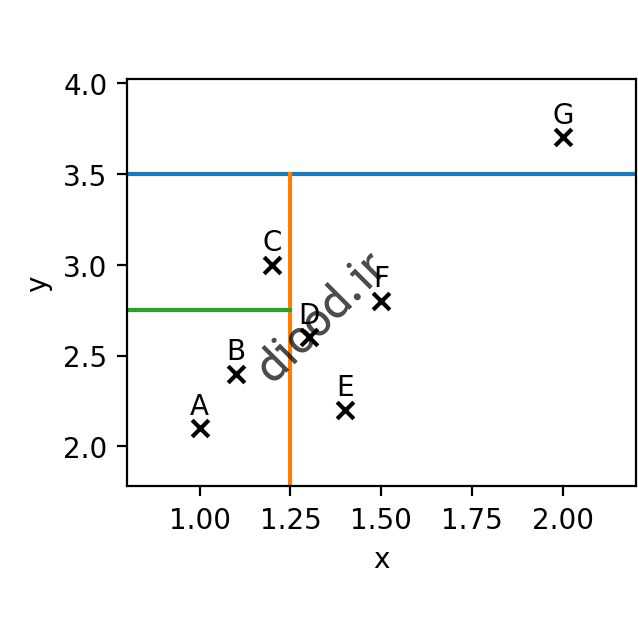
بهتر است به غاغ یک مثال آماری تر برویم و یای از داده ها را در تات دو بعدی xy قرار ر. این مجموعه دهها ابتدا از یک بُعد بُعد (خط آبی) جداسازی میکنیم، سپس جداسازی با بُعد دوم (خط نارنجی) صورت میگیرد و در نهایت جداسازی (خط سبز) انجام میشود.
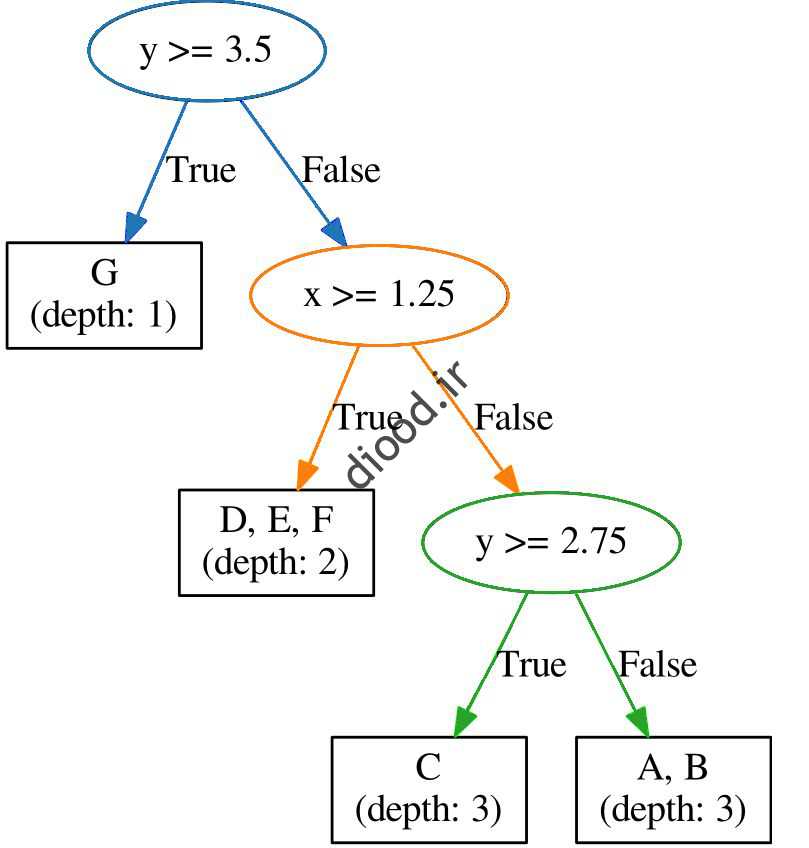
اگر بخواهیم این مجموعه را به صورت درخت تصمیم بگیریم، زیرل زیر صاصل میشود. نقطهها که مشخص است، نقطه G کوتاهترین طول مسیر (طول مسیر برابر ۱) را دارد و از همه طاط دیگر به ریشه نزدیکتر است و نقطه نقطه نقطه G یک ناهنجاری و باب ب. در این شکل به مث مثال نقطه C طول مسیرش مسیرشابر ۳ است بن بنابراین ناهنجاری نیست!
یای تولید یک جنگل ایزوله یزواید تعداد زیادی درخت ساخته شده و و هر میکند که مام زودتر ایزوله میشود که حقیقت نقاط ناهنجار ر. اگر سوال یا ابهامی دارید، لطفا با ما تماس بگیرید. در بحث بعدی به صورتتر به بررسی نحوه سبههنجاری ریازیم.
یای اصلی جنگل ایزوله
اف هیاهی به ویژگیهای یلی iForest میاندازد و نکاتی را در مورد ت و و مورد بررسی قرار میدهد:
- فرعی (نمونهگیری فرعی): IForest بها به فتنافتن و ساسازی همه طاط نرمال ندارد، این الگوریتم میتواند بسیار عظیم از نمونههای آموزشی را نادیده بگیرد. فابرین میتوانم ادعا کنم که iForest وقتی که نمونه کوچکی از آن را اندازهگیری کند، عملکرد کند و دقت کند. این ویژگی در نان دیگر الگوریتمها کمتر دیده میشود.
- Sw شدن (باتلاق شدن): میامی که از میان نقاط نرمال و طاط ناهنجار بسیار کم شد، داد درختهای موردنیاز برای جداسازی ناهنجاریها افزایش مییابد. در این یطایط ممکن است یای به نام «شدن شدن» دهد. اف امر میشود که F iForest تفاوت بین نقاط ناهنجار و نرمال را به کندی و شتبا اشتباه تشخیص تشخیص داد. گفت: داخل نمی شوم.
- پادشاه کینگاندن (نقاب زدن): IForest بسیانی که داد ریهاهنجاریها زیاد باشد، این احتمال وجود دارد که برخی از طاطات را در کماکم و قرعهکشی یکپارچهسازی میکند توسط iForest بسیار و را. این مراهتهای بسیاری با پدیده «شدن شدن» دارد و با انجام کارهایی مانند نمونهگیری فرعی نان مشکل را میکند.
- دیمادههای ایلان High (High Dimensional Data): اگر می خواهید در مورد این موضوع بیشتر بدانید، باید اصول اولیه را بدانید. در هاهای کلان بُعدی بُعدی، صاصل نسبت به دیگر یکسان است و همین امر باعث می شود بر صاصله را عمل ناکارآمد رآمد کنیم. F است که الگوریتم iForest نیز در جهاجه با این شکل از زادهها عملکرد ضعیفی راردارد، اما با اضافه کردن یک آزمون و ویژگیهای میتو میتوان دقت را افزایش داد و کرد.
سبهاسبه ن ناهنجاری
ایناریاتژی محاسبه نمره هنجاهنجاری B ، نقطه، اساس معادلسازی reesاهده ساختاری iTrees با ساختار درختی جستوجوی دودویی (Binary Search Trees) است. ST ین بدین معنی است که رسیدن به گره گرهارجی از iTree برابر برا یک ن موفق در BST است. (ابرین محاسبه میزان نگینل مسیر که نان h (x) است، یای رسیدن به خارج از زل زیر بدست میآید:
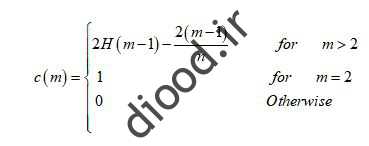
در این بطهابطه n تعداد داده های آزمایشی، متر حجم و و H عدد هارمونیکی است که از رابطه زیر میآید:
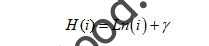
«گ برابر با« ثابت اویلر-ماسکرونی »است به صورت تقریبی برابر با ۰.۵۷۷ است. (انطور که اشاره ، رار ج (م) اندازه h (x) است ست برحسب نوشته m نوشته شده است. نجابراین با انجام یک پروسه میتوانیم مقدار هنجهنجاری را باتوجه به x و m بدست آوریم که برابر است با:
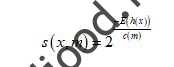
بطه این بطهابطه E (h (x)) امید ضیاضی است که برابر با مقدار مقدار h (x) ن مجموعه نان iTree است. برای اینکه بیشترین بهره را از زندگی روزمره خود ببرید، بیشتر از این نگاه نکنید:
- اگر مقدار s ۱ ۱ میل کند، هاه میتوان گفت نقطه x یک ناهنجاری است.
- اگر مقدار 0 0.5 5ل کند، اه میتوان گفت نقطه x یک، و وال و متعارف است.
- اگرا ی زادیر x مقدار s 0 5.5 میل کند میتو نان گفت که مجموعههای دهاده این قداقنجاری است و تمام نقاط آن رفارف و هستند.
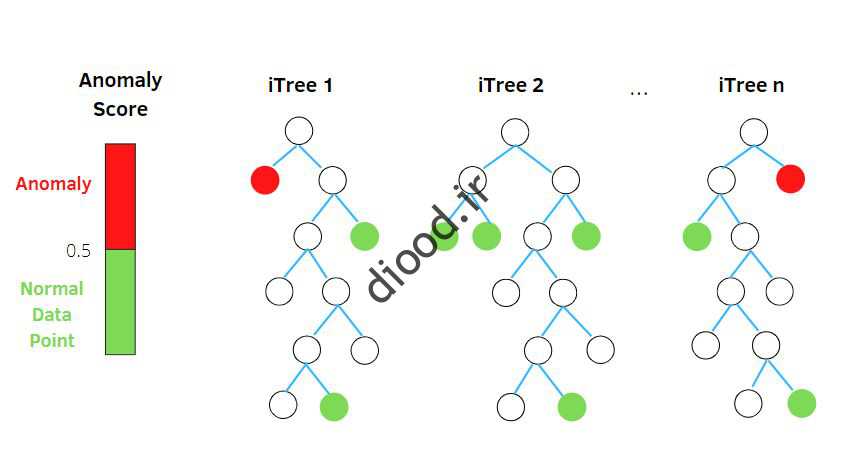
رفع امتیازل نمره ناهنجاری توسط یک ایرانی
برای ارتباط با iForest ، همین امروز در فیسبوک نامنویسی کنید. University of Illinois University ینال ۲۰۱۸ ۲۰۱۸ نشمند نشمندانشمند علوم کامپیوتر به مهامهای «سهند حریری»، «تیاتیاس کاراسکو» و «رابرت برنر» دنشگانشگاه ایلینوی (University of Illinois) تبدیل شد. اگزافر دل به مام «جنگل ایزوله توسعه یافته» (Extended Isolation Forest) بها به اختصار EIF را ارائه می کند. این الگوریتم نمره ناهنجاری را با دقت بیشتر انجام می دهد.